
cs11 R language
1 The Oregon Health Insurance Experiment, Revisited (16 points)
In this problem, you will continue to work with the data from Problem Set #1, Q2. Please refer back to Problem Set 1 for variable definitions.
For this assignment, you can refer to any output that comes from the lm() function in R.
1. In Problem Set Q2.1, we found that one of the baseline characteristics, numhh list, was statistically significant from zero at the 5 percent level. Oh no, did randomization fail? It
turns out that the researchers expected this. The reason this happened is because treatment was assigned at the household level, and households with more eligible individuals had more
chances to win the lottery. Fortunately, we can easily deal with this violation of balance using multivariate regression techniques!
The regression controlling for family size is given as follows:
Y = β0 + β1T reated + β2numhh list + u
Recall in problem set #1, you ran the following regression:
Y = β′0+ β′1 Treated + v
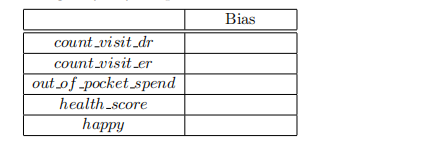
For each of the five outcomes, calculate the bias from not including numhh list as a control, filling in the table below. Are any of these biases quantitatively large enough to fundamentally
change any of your qualitative conclusions about the OHIE? (3 points)
my wechat:_0206girl
Don't hesitate to contact me

